Different industries and different use-cases will require different data platforms designs and architectures.
Its important to know that architecture designs and drawings are only half the story; they only show what connects to what. They don’t show the philosophy behind the design. Two teams can take the same architectural drawing and produce two different systems.
The Data Lake Platform (or Lakehouse)
The focus of a Data Lake based Data Platform is the storage of data “as is”, but if storage of raw data is all that’s required, then its a Data Lake. The transition of a Data Lake to a Data Platform comes from adding accessibility functionsality and perhaps Data Quality, Data Governance or processing capabilities.
Even though the data is stored “as is”, creating a degree of abstraction
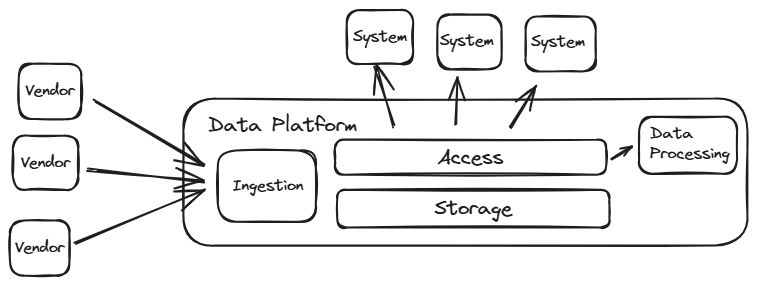
Components Required : Storage, Orchestration, Ingestion, Access
Optional : Data Quality, Data Lineage, Semantic Layer
The Data Bus Platform (Distribution)
The focus on a Distribution based Data Platform is to act a centralised Data Hub for an organisation. Organisations where data is shared between multiple departments or teams would benefit from having a single storage unit acting like a “data bus” rather than use point to point data transfers.
An Ingestion layer is optional as it could be left up to the individual feeder systems to load the data themselves. Each may have a preference for their ingestion methods. However, as the Data Platform grows in use, the nature tendency is to build one loading mechanism used by all.
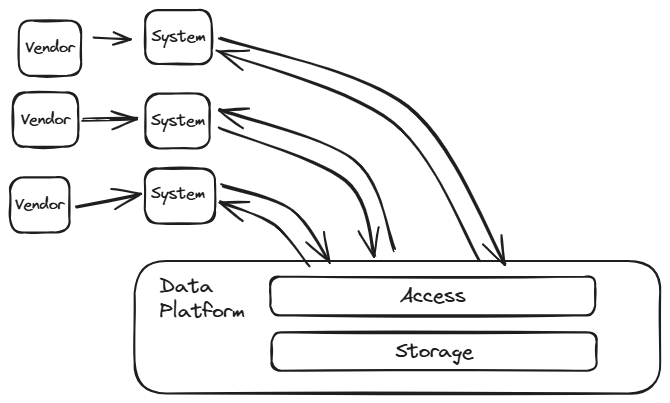
This design will form the basis of a “Data Coherence Data Platform“.
Components Required : Storage, Access
Optional : Ingestion, Dissemination, Data Quality, Data Lineage, Semantic Layer
The “Two Pillars” Platform
The “Two Pillars” Platform is a combination of a Data Lake Platform and a Distribution Platform. The transformation layer could be omitted as each data consumer could perform its own transformation to the data it required.
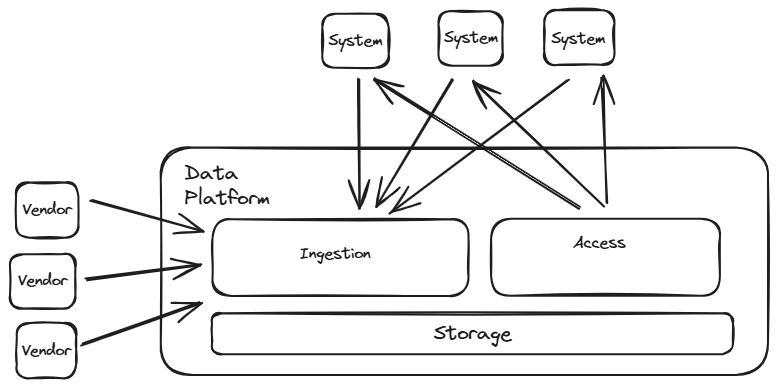
Components Required : Storage, Orchestration, Ingestion, Access
Optional : Ingestion, Data Quality, Data Lineage, Semantic Layer
The “Full Monty” Platform
The full Data Platform fits organisations pulling in 3rd party data which requires re-modelling, facilitating access to the data for all teams and storing internally produced data for others to consume, either internally or externally.
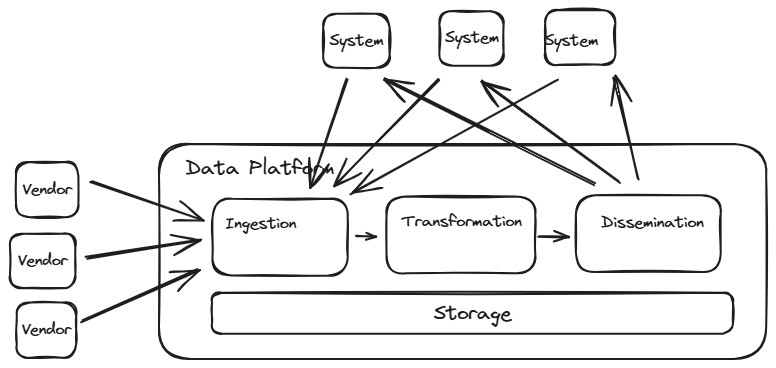
Components Required : Storage, Orchestration, Ingestion, Transformation, Access
Optional : Data Quality, Data Lineage, Semantic Layer